Hoje iremos discutir a teoria ergodica do fluxo homogêneo 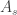


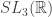

o qual é o produto semi-direto 
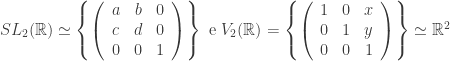
Além disso, identificamos o espaço de lattices 
(1) 
Finalmente, nos concluimos que todas essas identificações reduziam nossa tarefa na prova do seguinte fato (enunciado como teorema 3 no post anterior):
Teorema 0. Para toda
vale
.
Como ja antecipamos, este resultado sera obtido de um teorema mais geral sobre equidistribuição de horociclos não-lineares. Para enunciar adequadamente este teorema, vamos introduzir a definição:
Definição 1. Uma seção horociclica (ou horociclo) é uma aplicação 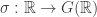
(2)
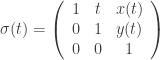
tal que

para algum inteiro 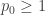

Observação 1. Dado um horociclo 
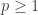

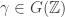

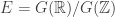
Observação 2. O nome horociclo tem a seguinte motivação: a projeção natural do espaço de lattices 
Definição 2. Um horociclo 
![m\left(\{t\in[0,p]: x(t)=\alpha t+\beta\}\right)>0](https://s0.wp.com/latex.php?latex=m%5Cleft%28%5C%7Bt%5Cin%5B0%2Cp%5D%3A+x%28t%29%3D%5Calpha+t%2B%5Cbeta%5C%7D%5Cright%29%3E0&bg=ffffff&fg=333333&s=0&c=20201002)
Caso contrario, o horociclo
Observação 3. O comportamento de 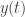
Observação 4. Um horociclo real-analitico 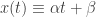
Comparando as equações (1), (2) e utilizando a observação 4, vemos que

forma um horociclo não-linear com periodo 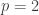
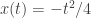
Teorema 1 (Equidistribuição de horociclos). Seja
ficam equidistribuidos em
.
Observação 5. Os ingredientes importantes neste resultado são: a “parte linear” do horociclo ser uma matriz unipotente e o horociclo é não-linear. Com efeito, na prova do teorema 1 iremos usar o fato do horociclo ter parte linear unipotente para aplicar o teorema de Ratner de modo a reduzir a lei de distribuição 

Observação 6. A hipotese do horociclo ser não-linear é essencial: quando o horociclo é linear, o resultado do teorema 1 é falso! Voltaremos nesse ponto apos vermos a prova do teorema.
Com isso, dedicaremos o resto deste post para a demonstração do teorema 1. Para isso, vamos utilizar o seguinte esquema:
- na proxima seção, revisaremos alguns fatos basicos sobre medidas invariantes e veremos algumas propriedades da medida
;
- em seguida, usaremos o teorema de Ratner para mostrar que temos apenas uma quantidade enumeravel de possibilidades para a lei de distribuição
- finalmente, na ultima seção utilizaremos a não-linearidade do horociclo
, o que terminara a prova do teorema 1.
Agora passamos para a formalização desse programa.
–A lei de distribuição de um ”loop”–
Dado um ”loop” 
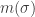

para
Além disso, dado 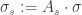
Teorema 2 (Equidistribuição de horociclos versão 2). Para todo horociclo não-linear
quando
.
Como de costume, aqui a convergência ocorre na topologia fraca-*. Pelo teorema de Banach-Alaoglu, sabemos que 
Para isso, consideramos a aplicação 


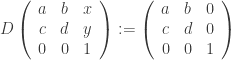
Observe que a projeção da medida de Haar 
Proposição 1. Temos que
.
Prova. A imagem 
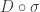
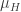

Isto termina a prova.

Observação 7. Uma consequência direta da proposição 1 é que 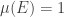
Como veremos mais tarde, para entrarmos no contexto do teorema de Ratner, precisamos saber que 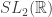

Note que este subgrupo unipotente aparece naturalmente em vista da formula 

Proposição 2. A probabilidade
-invariante.
Prova. Fixamos 



Para comparar adequadamente 


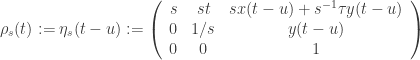
Lembrando que 
(3) 
Por outro lado, temos que 

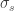

Em seguida, usamos o fato de 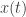

e
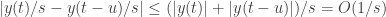
Portanto, vemos que 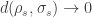


o que encerra a demonstração.
Uma vez que ja temos a invariância de
–Teorema de Ratner e a classificação de
O teorema de Ratner pode ser enunciado assim:
Teorema de Ratner. Sejam
um subgrupo discreto de um grupo de Lie conexo
e
um subgrupo unipotente. Seja
uma probabilidade ergodica
e denote por
o maior subgrupo de
tal que
. Além disso,
e o suporte de
A importância do teorema de Ratner para o contexto do teorema de Elkies e McMullen fica evidente: sendo
Logicamente o teorema de Ratner tem uma bela historia incluindo varias aplicações em ramos diversos da Matematica. Por isso, ficaria impossivel fazer jus a relevância desse teorema numa discussão breve, de modo que recomendamos o leitor interessado numa exposição profunda do assunto (incluindo algumas ideias da prova em casos particulares, motivação heuristica para a validade do enunciado acima e algumas aplicações) os posts publicados no blog do prof. Terence Tao (veja aqui um link para estes posts).
Em todo caso, nos iremos utilizar o teorema de Ratner do seguinte jeito. Denotando por 

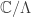
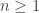
![F[n]=\left(\frac{1}{n}\cdot\Lambda\right)/\Lambda\subset F](https://s0.wp.com/latex.php?latex=F%5Bn%5D%3D%5Cleft%28%5Cfrac%7B1%7D%7Bn%7D%5Ccdot%5CLambda%5Cright%29%2F%5CLambda%5Csubset+F&bg=ffffff&fg=333333&s=0&c=20201002)

![E[n]](https://s0.wp.com/latex.php?latex=E%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![F[n]](https://s0.wp.com/latex.php?latex=F%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002)
Definição 3. ![\bigcup E[n]](https://s0.wp.com/latex.php?latex=%5Cbigcup+E%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002)
Em seguida introduzimos 



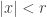

O objetivo dessa seção é aplicar o teorema de Ratner para mostrar o seguinte resultado:
Teorema 4 (Classificação de
para algum
Infelizmente o teorema 4 não é uma consequência imediata do teorema de Ratner porque não sabemos que
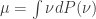
Observação 8. Usualmente o teorema de decomposição ergodica é enunciado em espaços compactos. No caso de
Em seguida, para cada

ou seja, 


Proposição 3. Para quase toda
.
Prova. Da proposição 1 sabemos que 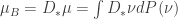
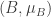

Por outro lado, pelo teorema de Ratner sabemos que 
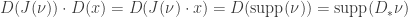
Como ja vimos que

Portanto, 
Agora nos relembramos a seguinte proposição sobre ações de
Proposição 4. Toda ação afim de
possui pontos fixos.
Prova. Pelo truque unitario de Weyl, esta ação pode ser estendida para uma ação de 
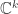


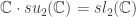
Proposição 5. Se
é um subgrupo com
, então
ou
Prova. Como 


: nesse caso,
: nesse caso, temos uma ação afim
de
, a qual deve possuir um ponto fixo pela proposição 4; conjugando com um elemento adequado de
, podemos assumir que este ponto fixo é a origem e
.
Isto termina a demonstração.
Corolario 1.
ou
para alguma translação horizontal
.
Prova. Como
Proposição 6.
ou
para algum
Prova. Do corolario anterior temos 
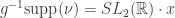
Neste ponto, podemos finalizar esta seção dando a demonstração do teorema 4:
Prova do teorema 4. Escremos a decomposição ergodica de 

![\textrm{supp}(\nu)\subset H(\mathbb{R})\cdot E[n]](https://s0.wp.com/latex.php?latex=%5Ctextrm%7Bsupp%7D%28%5Cnu%29%5Csubset+H%28%5Cmathbb%7BR%7D%29%5Ccdot+E%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002)

onde 
![\textrm{supp}(\mu_n)\subset H(\mathbb{R})\cdot E[n]](https://s0.wp.com/latex.php?latex=%5Ctextrm%7Bsupp%7D%28%5Cmu_n%29%5Csubset+H%28%5Cmathbb%7BR%7D%29%5Ccdot+E%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002)

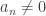
Tendo em vista a classificação de
–Não-linearidade e pontos de torção–
O teorema principal dessa seção é
Teorema 5. Dados
(quando
para todo
Prova. Dados 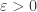
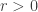
![U=H(r,\varepsilon)\cdot E[n]](https://s0.wp.com/latex.php?latex=U%3DH%28r%2C%5Cvarepsilon%29%5Ccdot+E%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002)
e
![T_s=\{t\in [0,p]: \sigma_s(t)\in U\}](https://s0.wp.com/latex.php?latex=T_s%3D%5C%7Bt%5Cin+%5B0%2Cp%5D%3A+%5Csigma_s%28t%29%5Cin+U%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002)
Afirmamos que
(4) 
Para computar 
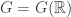

![G[n]=\bigcup G[n]^{i,j}](https://s0.wp.com/latex.php?latex=G%5Bn%5D%3D%5Cbigcup+G%5Bn%5D%5E%7Bi%2Cj%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![G[n]^{i,j}=\left\{\left(\begin{array}{ccc}a&b&\frac{i}{n}a+\frac{j}{n}b \\ c&d& \frac{i}{n}c+\frac{j}{n}d\\ 0&0&1\end{array}\right): ad-bc=1\right\}](https://s0.wp.com/latex.php?latex=G%5Bn%5D%5E%7Bi%2Cj%7D%3D%5Cleft%5C%7B%5Cleft%28%5Cbegin%7Barray%7D%7Bccc%7Da%26b%26%5Cfrac%7Bi%7D%7Bn%7Da%2B%5Cfrac%7Bj%7D%7Bn%7Db+%5C%5C+c%26d%26+%5Cfrac%7Bi%7D%7Bn%7Dc%2B%5Cfrac%7Bj%7D%7Bn%7Dd%5C%5C+0%260%261%5Cend%7Barray%7D%5Cright%29%3A+ad-bc%3D1%5Cright%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002)
Em particular os pontos de ![G[n]](https://s0.wp.com/latex.php?latex=G%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002)
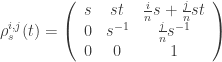
Tomando a métrica Euclideana na terceira coluna das matrizes acima, vemos que 
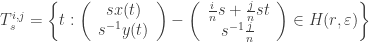
Em particular, 

e

Neste ponto vamos usar a não-linearidade de 
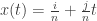
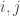
(5) 
Por outro lado, utilizamos o fato de 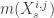



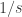
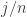
(6) 

Além disso, notamos que
(7) 
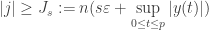
e
( 8 ) 

Finalmente, observamos que
(9) 


Com estes fatos em mãos, podemos estimar
(10) 
Agora dividimos a soma do lado direito em duas partes:

Em seguida, notamos que a primeira soma é 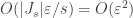
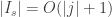
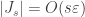
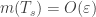
o que prova a estimativa (4) desejada.
Finalmente, lembramos que 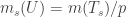
![\mu(H(r,\varepsilon)\cdot E[n])=O(\varepsilon)](https://s0.wp.com/latex.php?latex=%5Cmu%28H%28r%2C%5Cvarepsilon%29%5Ccdot+E%5Bn%5D%29%3DO%28%5Cvarepsilon%29&bg=ffffff&fg=333333&s=0&c=20201002)



![\mu(H(\mathbb{R})\cdot E[n])=0](https://s0.wp.com/latex.php?latex=%5Cmu%28H%28%5Cmathbb%7BR%7D%29%5Ccdot+E%5Bn%5D%29%3D0&bg=ffffff&fg=333333&s=0&c=20201002)
Com o teorema 5 ja provado, a tarefa de concluir a demonstração do teorema 2 (ou equivalentemente do teorema 1) fica facil. Com efeito esse é o conteudo da (curta) seção final abaixo.
–Fim da prova do teorema 2–
Dado ![\bigcup\limits_{n\geq 1} E[n]](https://s0.wp.com/latex.php?latex=%5Cbigcup%5Climits_%7Bn%5Cgeq+1%7D+E%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002)

o que encerra a prova do teorema 2.
Com isso, nossa apresentação da prova do teorema de Elkies e McMullen chega ao fim! Para fechar este post, fazemos a seguinte observação:
Observação 9. O teorema 2 de equidistribuição é optimal, i.e., ele nunca vale quando ![\mu(E[n])>0](https://s0.wp.com/latex.php?latex=%5Cmu%28E%5Bn%5D%29%3E0&bg=ffffff&fg=333333&s=0&c=20201002)
 ao longo dos latti- ces
ao longo dos latti- ces 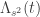 (na notação do
(na notação do ![\{\Lambda_{s^2}(t): t\in [0,1]\}](https://s0.wp.com/latex.php?latex=%5C%7B%5CLambda_%7Bs%5E2%7D%28t%29%3A+t%5Cin+%5B0%2C1%5D%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002) de circu- los de lattices fica equidistribuida no espaço de lattices
de circu- los de lattices fica equidistribuida no espaço de lattices  quando
quando 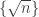 .
.![t\in [0,1]](https://s0.wp.com/latex.php?latex=t%5Cin+%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) tais que
tais que  é
é  . Juntando este fato com o teorema 1 acima, temos a seguinte consequência:
. Juntando este fato com o teorema 1 acima, temos a seguinte consequência: temos
temos quando
quando  . Com essa notação, o fato do tamanho do conjunto dos
. Com essa notação, o fato do tamanho do conjunto dos 
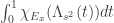 converge para
converge para 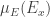 . Para isso, a idéia natural seria aplicar o teorema 1. Entretanto uma utilização direta desse teorema não é possivel porque a função caracteristica
. Para isso, a idéia natural seria aplicar o teorema 1. Entretanto uma utilização direta desse teorema não é possivel porque a função caracteristica  não é continua. Um remédio simples para esse contra-tempo é aproximar (em
não é continua. Um remédio simples para esse contra-tempo é aproximar (em 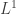 )
)  por funções continuas em
por funções continuas em 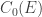 e aplicar o teorema 1. Com isso, a unica coisa que nos resta fazer é ver que tais aproximações exis- tem. Conforme sabemos dos cursos de analise, as funções
e aplicar o teorema 1. Com isso, a unica coisa que nos resta fazer é ver que tais aproximações exis- tem. Conforme sabemos dos cursos de analise, as funções  podem ser aproximadas por funções em
podem ser aproximadas por funções em  .
.![L:E\to [0,\infty]](https://s0.wp.com/latex.php?latex=L%3AE%5Cto+%5B0%2C%5Cinfty%5D&bg=ffffff&fg=333333&s=0&c=20201002) é uma
é uma  contendo a origem
contendo a origem  ou um ponto do lado horizontal
ou um ponto do lado horizontal  do seu triângulo maximal
do seu triângulo maximal  . Em particular, para cada
. Em particular, para cada  , os pontos de
, os pontos de 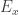 nos quais
nos quais 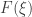 de
de 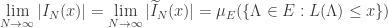
 assintoticamente em termos da medida
assintoticamente em termos da medida ![L^{-1}([0,x])](https://s0.wp.com/latex.php?latex=L%5E%7B-1%7D%28%5B0%2Cx%5D%29&bg=ffffff&fg=333333&s=0&c=20201002) ), ainda não estamos em condições de computar a distri- buição
), ainda não estamos em condições de computar a distri- buição 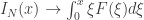 , de modo que para obter
, de modo que para obter ![\mu_E(L^{-1}([0,x]))](https://s0.wp.com/latex.php?latex=%5Cmu_E%28L%5E%7B-1%7D%28%5B0%2Cx%5D%29%29&bg=ffffff&fg=333333&s=0&c=20201002) devemos derivar em
devemos derivar em  de
de 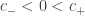 . Observe que
. Observe que 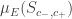 depende apenas da area
depende apenas da area 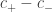 do triângulo
do triângulo ![p:[0,\infty]\to [0,1]](https://s0.wp.com/latex.php?latex=p%3A%5B0%2C%5Cinfty%5D%5Cto+%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) por
por
 e
e 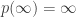 .
. 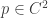 (i.e.,
(i.e.,  é continua). Então,
é continua). Então,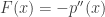 .
. em “soma telescopica” assim:
em “soma telescopica” assim:![\mu_E(S_{0,x}) - \lim\limits_{M\to\infty} \sum\limits_{j=0}^{M-1} [\mu_E(S_{\frac{(j+1)x}{M}-x, \frac{jx}{M}})-\mu_E(S_{\frac{jx}{M}-x,\frac{jx}{M}})]](https://s0.wp.com/latex.php?latex=%5Cmu_E%28S_%7B0%2Cx%7D%29+-+%5Clim%5Climits_%7BM%5Cto%5Cinfty%7D+%5Csum%5Climits_%7Bj%3D0%7D%5E%7BM-1%7D+%5B%5Cmu_E%28S_%7B%5Cfrac%7B%28j%2B1%29x%7D%7BM%7D-x%2C+%5Cfrac%7Bjx%7D%7BM%7D%7D%29-%5Cmu_E%28S_%7B%5Cfrac%7Bjx%7D%7BM%7D-x%2C%5Cfrac%7Bjx%7D%7BM%7D%7D%29%5D&bg=ffffff&fg=333333&s=0&c=20201002) .
. .
. .
.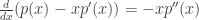 . Mais ainda, como
. Mais ainda, como  em
em 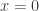 . Combinando esses dois fatos, obtemos que
. Combinando esses dois fatos, obtemos que 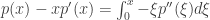 .
.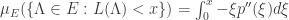 .
. .
. 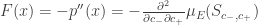
 . Isto fornece a se- guinte interpretação geométrica para
. Isto fornece a se- guinte interpretação geométrica para 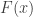 em termos de
em termos de 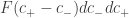 é a medida do conjunto de lattices
é a medida do conjunto de lattices  intersectando
intersectando 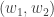 verificando
verificando  e o outro com coordenadas
e o outro com coordenadas 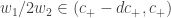 .
.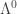 isomorfos a
isomorfos a  com covolume 1) e
com covolume 1) e  de uma rede
de uma rede  é dito primitivo sempre que existir
é dito primitivo sempre que existir  tal que
tal que  é uma
é uma  é primitivo quando
é primitivo quando  para todo
para todo 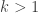 . No que se segue iremos utilizar os seguintes fatos:
. No que se segue iremos utilizar os seguintes fatos: de redes possuindo
de redes possuindo  como um vetor primitivo forma um circulo (na verdade um
como um vetor primitivo forma um circulo (na verdade um 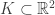 um compacto convexo, a area de
um compacto convexo, a area de  onde
onde  é a quantidade de vetores primitivos de
é a quantidade de vetores primitivos de  para todo
para todo 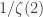 vezes a area de
vezes a area de 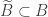 assim:
assim:  , onde
, onde  é a medida (normalizada) de Lebesgue do circulo
é a medida (normalizada) de Lebesgue do circulo  .
. e
e 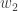 coordenadas
coordenadas  dos vetores de
dos vetores de 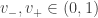 , escrevemos
, escrevemos  e lembramos que
e lembramos que ![q_x(v_-,v_+)\in [0,1]](https://s0.wp.com/latex.php?latex=q_x%28v_-%2Cv_%2B%29%5Cin+%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) a (
a (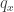 ao invés de
ao invés de  porque essa quantidade depende apenas de
porque essa quantidade depende apenas de  . Com essa notação, a formula de
. Com essa notação, a formula de  é continua exceto num subconjunto de
é continua exceto num subconjunto de 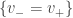 . Mais ainda, para
. Mais ainda, para  .
. ser continuo é imediato exceto quando o vetor
ser continuo é imediato exceto quando o vetor  . No mais, como
. No mais, como 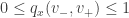 , a integral dupla acima existe e varia continuamente com
, a integral dupla acima existe e varia continuamente com 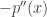 e
e  ser o produto dos comprimentos dos segmentos de reta
ser o produto dos comprimentos dos segmentos de reta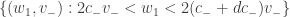
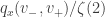 na formula de desintegração de
na formula de desintegração de  levando o triângulo
levando o triângulo 
 . Como o triângulo
. Como o triângulo  .
. e
e 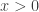 vale
vale  . Além disso, para
. Além disso, para  , temos
, temos
 . Aqui estamos interpretando
. Aqui estamos interpretando
![F(t):=\begin{cases}6/\pi^2, \quad t\in [0,1/2], \\ F_2(t), \quad t\in[1/2,2], \\ F_3(t), \quad t\in [2,\infty), \end{cases}](https://s0.wp.com/latex.php?latex=F%28t%29%3A%3D%5Cbegin%7Bcases%7D6%2F%5Cpi%5E2%2C+%5Cquad+t%5Cin+%5B0%2C1%2F2%5D%2C+%5C%5C+F_2%28t%29%2C+%5Cquad+t%5Cin%5B1%2F2%2C2%5D%2C+%5C%5C+F_3%28t%29%2C+%5Cquad+t%5Cin+%5B2%2C%5Cinfty%29%2C+%5Cend%7Bcases%7D&bg=ffffff&fg=333333&s=0&c=20201002)
 e
e 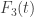 são
são
 .
.![\psi(r) = \tan^{-1}[(2r-1)/\sqrt{4r-1}] - \tan^{-1}[1/\sqrt{4r-1}]](https://s0.wp.com/latex.php?latex=%5Cpsi%28r%29+%3D+%5Ctan%5E%7B-1%7D%5B%282r-1%29%2F%5Csqrt%7B4r-1%7D%5D+-+%5Ctan%5E%7B-1%7D%5B1%2F%5Csqrt%7B4r-1%7D%5D&bg=ffffff&fg=333333&s=0&c=20201002) ,
,  ,
, 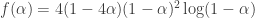 ,
,  e
e 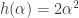 .
. .
. .
. o subgrupo formado pelas matrizes com entradas inteiras e observamos que o espaço de lattices (uni- modulares)
o subgrupo formado pelas matrizes com entradas inteiras e observamos que o espaço de lattices (uni- modulares)  associamos o lattice
associamos o lattice .
.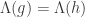 se e so se
se e so se  (como o leitor pode verificar), de maneira que isto é um isomor- fismo entre
(como o leitor pode verificar), de maneira que isto é um isomor- fismo entre  ,
,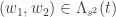 em notação matricial ficam:
em notação matricial ficam: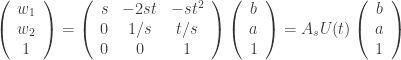 ,
,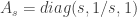 é a matriz diagonal
é a matriz diagonal
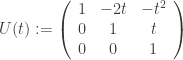 .
.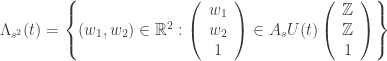 .
.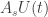 . Resumindo, vemos que o teorema 1 é equivalente ao seguinte enunciado:
. Resumindo, vemos que o teorema 1 é equivalente ao seguinte enunciado:![\{A_sU(t):t\in [0,1]\}](https://s0.wp.com/latex.php?latex=%5C%7BA_sU%28t%29%3At%5Cin+%5B0%2C1%5D%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002) ficam e- quidistribuidos em
ficam e- quidistribuidos em 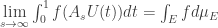 .
.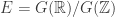 : mais precisamente, iremos explorar o fato do circulo
: mais precisamente, iremos explorar o fato do circulo ![\{U(t):t\in[0,1]\}](https://s0.wp.com/latex.php?latex=%5C%7BU%28t%29%3At%5Cin%5B0%2C1%5D%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002) ser um horociclo não-linear (um con- ceito a ser discutido depois) para derivar o teorema 3 de um re- sultado mais geral sobre a equidistribuição de horociclos não-li- neares pelo fluxo de
ser um horociclo não-linear (um con- ceito a ser discutido depois) para derivar o teorema 3 de um re- sultado mais geral sobre a equidistribuição de horociclos não-li- neares pelo fluxo de  (mod 1) exposto no penultimo paragrafo do
(mod 1) exposto no penultimo paragrafo do  é uma rede se
é uma rede se  é um subgrupo discreto isomorfo à
é um subgrupo discreto isomorfo à  tem area 1. Além disso, um lattice
tem area 1. Além disso, um lattice 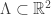 é um subconjunto da forma
é um subconjunto da forma  onde
onde 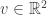 e
e 
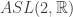 é o grupo de transformações afins
é o grupo de transformações afins  da forma
da forma  com
com  e
e  é o subgrupo discreto de
é o subgrupo discreto de 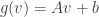 satisfazem
satisfazem 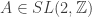 e
e  .
.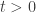 e
e ![I=[x,x+t/N]\subset\mathbb{R}/\mathbb{Z}](https://s0.wp.com/latex.php?latex=I%3D%5Bx%2Cx%2Bt%2FN%5D%5Csubset%5Cmathbb%7BR%7D%2F%5Cmathbb%7BZ%7D&bg=ffffff&fg=333333&s=0&c=20201002) , onde
, onde ![x\in [0,1]](https://s0.wp.com/latex.php?latex=x%5Cin+%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) é tomado aleatoriamente (com relação a medida de Lebesgue). Nesses termos, o programa da demonstração sera o seguinte:
é tomado aleatoriamente (com relação a medida de Lebesgue). Nesses termos, o programa da demonstração sera o seguinte: de
de  conter algum ponto
conter algum ponto 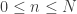 ;
;
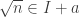 para algum
para algum 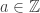
 para algum
para algum  por sua aproximação linear
por sua aproximação linear ;
; de
de  (para
(para 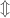
 (para
(para  )
) onde
onde 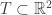 é o triângulo de area
é o triângulo de area ![T:=\{(a,b): b+x^2\in 2(a+x)I \textrm{ e } a+x\in [0,\sqrt{N}]\}](https://s0.wp.com/latex.php?latex=T%3A%3D%5C%7B%28a%2Cb%29%3A+b%2Bx%5E2%5Cin+2%28a%2Bx%29I+%5Ctextrm%7B+e+%7D+a%2Bx%5Cin+%5B0%2C%5Csqrt%7BN%7D%5D%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002) .
.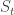 o triângulo “padrão” de area
o triângulo “padrão” de area  e considerando
e considerando 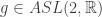 a unica transformação afim com
a unica transformação afim com  e
e 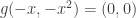 , podemos reescrever a condição anterior como
, podemos reescrever a condição anterior como ;
;![I=[x,x+t/N]](https://s0.wp.com/latex.php?latex=I%3D%5Bx%2Cx%2Bt%2FN%5D&bg=ffffff&fg=333333&s=0&c=20201002) conter algum elemento
conter algum elemento  intersectar o triângulo padrão
intersectar o triângulo padrão 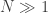 grande espera-se que
grande espera-se que  se comporte como um lattice aleatorio: de fato, assim como todo bom lattice aleatorio, temos que a sequência
se comporte como um lattice aleatorio: de fato, assim como todo bom lattice aleatorio, temos que a sequência  é uniformemente distribuida – para toda
é uniformemente distribuida – para toda  função continua de suporte compacto de
função continua de suporte compacto de  quando
quando 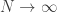
 quando
quando 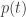 é a probabilidade de um lattice aleatorio intersectar o triângulo padrão
é a probabilidade de um lattice aleatorio intersectar o triângulo padrão 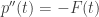 , onde
, onde 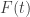 é a distribuição de lacunas de
é a distribuição de lacunas de  pode ser calculado explicitamente através de formulas naturais para a medida
pode ser calculado explicitamente através de formulas naturais para a medida 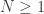 inteiro, definimos a função
inteiro, definimos a função ![\lambda_N:[0,\infty)\to [0,1]](https://s0.wp.com/latex.php?latex=%5Clambda_N%3A%5B0%2C%5Cinfty%29%5Cto+%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) assim. Consideramos os
assim. Consideramos os  , do circulo
, do circulo 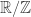 . Isso fornece uma partição do circulo em
. Isso fornece uma partição do circulo em 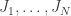 dos quais
dos quais 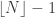 tem tamanho zero (estes intervalos são as lacunas de
tem tamanho zero (estes intervalos são as lacunas de  ,
, 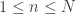 ). Nessa notação,
). Nessa notação,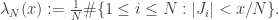
 :
: é não-decrescente e continua pela esquerda (de fato,
é não-decrescente e continua pela esquerda (de fato,  e
e  ;
; (porque
(porque  é a soma dos comprimentos das lacunas);
é a soma dos comprimentos das lacunas);![\lambda_{\infty}:[0,\infty)\to [0,1]](https://s0.wp.com/latex.php?latex=%5Clambda_%7B%5Cinfty%7D%3A%5B0%2C%5Cinfty%29%5Cto+%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) tal que
tal que 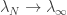 uniformemente em compactos quando
uniformemente em compactos quando  ,
, , a quantidade de lacunas de
, a quantidade de lacunas de  e
e  é assintotico à
é assintotico à 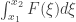 .
.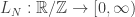 dada por
dada por
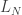 podemos escrever a união das lacunas de tamanho
podemos escrever a união das lacunas de tamanho  como
como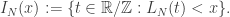
 , de maneira que o teorema 1 equivale à:
, de maneira que o teorema 1 equivale à: uniformemente para
uniformemente para 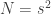 com
com  . Mais precisamente, temos o seguinte enunciado:
. Mais precisamente, temos o seguinte enunciado: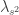 converge unif. em compactos para uma função continua
converge unif. em compactos para uma função continua  quando
quando 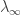 quando
quando 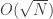 de um quadrado perfeito
de um quadrado perfeito 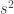 . Por outro lado, a troca de
. Por outro lado, a troca de  dos tamanhos das lacunas (ao maximo) e multiplica o fator normalizante
dos tamanhos das lacunas (ao maximo) e multiplica o fator normalizante  por
por 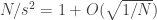 . Em particular, segue que
. Em particular, segue que  unif. em compactos implica
unif. em compactos implica  unif. em compactos.
unif. em compactos.  onde
onde 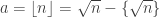 . Utilizando o lema 1, podemos assumir que
. Utilizando o lema 1, podemos assumir que  . Nessa situação, vemos que
. Nessa situação, vemos que
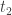 é o menor numero real
é o menor numero real 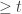 com
com 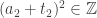 para algum
para algum  inteiro e
inteiro e 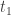 é o maior numero real
é o maior numero real  com
com 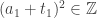 para algum
para algum  inteiro. Para entender melhor a função
inteiro. Para entender melhor a função  (
( ), temos que
), temos que  se e so se
se e so se  . Além disso, temos
. Além disso, temos 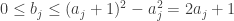 quando
quando  .
.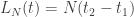 como
como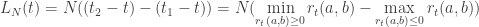 onde
onde 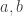 variam sobre os inteiros satisfazendo
variam sobre os inteiros satisfazendo e
e  .
. é superflua: por um lado,
é superflua: por um lado,  e por outro lado
e por outro lado  e
e  estão entre 0 e 1 ja que
estão entre 0 e 1 ja que 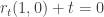 e
e 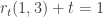 .
.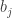 (feita na obs. 1), trocamos
(feita na obs. 1), trocamos 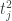 pela sua aproximação linear
pela sua aproximação linear  em torno de
em torno de  . Por esse motivo, vamos considerar
. Por esse motivo, vamos considerar  a solução da equação
a solução da equação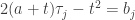
 por
por 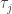 na definição de
na definição de 
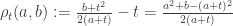 e
e  , definimos
, definimos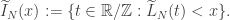
 converge unif. em compactos para
converge unif. em compactos para  com
com 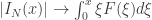
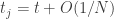 , de modo que
, de modo que  (ja que
(ja que  ). Mais ainda, dado
). Mais ainda, dado  para a “maioria” dos pares
para a “maioria” dos pares 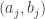 . Portanto, a expectativa é que a troca de
. Portanto, a expectativa é que a troca de  , o que não altera o comportamento assintotico de
, o que não altera o comportamento assintotico de 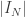 .
.![\frac{\rho_t(a,b)}{r_t(a,b)} = \frac{\sqrt{a^2+b}+a+t}{2(a+t)}\in [\frac{2a+1}{2a+2}, \frac{2a+1}{2a}]](https://s0.wp.com/latex.php?latex=%5Cfrac%7B%5Crho_t%28a%2Cb%29%7D%7Br_t%28a%2Cb%29%7D+%3D+%5Cfrac%7B%5Csqrt%7Ba%5E2%2Bb%7D%2Ba%2Bt%7D%7B2%28a%2Bt%29%7D%5Cin+%5B%5Cfrac%7B2a%2B1%7D%7B2a%2B2%7D%2C+%5Cfrac%7B2a%2B1%7D%7B2a%7D%5D&bg=ffffff&fg=333333&s=0&c=20201002) .
. . Além disso, para todo
. Além disso, para todo  , temos que a estimativa
, temos que a estimativa
![t\in[0,1]](https://s0.wp.com/latex.php?latex=t%5Cin%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) exceto para um conjunto de tamanho
exceto para um conjunto de tamanho 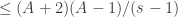 .
.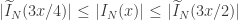

 . Usando essas estimativas com
. Usando essas estimativas com  (ou qualquer outra função crescente de
(ou qualquer outra função crescente de  ), obtemos o teorema 3.
), obtemos o teorema 3. . Para isso, faremos na proxima seção a interpretação dessa quantidade em termos de lattices conforme proposto os pontos 5, 6, 7 e 8 do programa de Elkies e McMullen.
. Para isso, faremos na proxima seção a interpretação dessa quantidade em termos de lattices conforme proposto os pontos 5, 6, 7 e 8 do programa de Elkies e McMullen. –
– conveniente (cuja forma ja explicitamos). Com nossa notação atual,
conveniente (cuja forma ja explicitamos). Com nossa notação atual,  cujo interior é determinado pelas desigualdades
cujo interior é determinado pelas desigualdades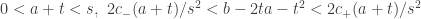 ,
, , então
, então  é a area
é a area 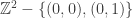 ;
;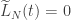 , então todos triângulos
, então todos triângulos 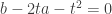 com
com 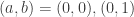 não afetam
não afetam  :
: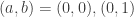 exceto se
exceto se 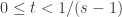 ou
ou  .
.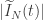 (ja que esta modificação altera os valores de
(ja que esta modificação altera os valores de  de
de 
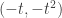 na origem
na origem 
 dado por
dado por .
. mas não de
mas não de  (para efeitos de comparação, esse triângulo corresponde ao triângulo
(para efeitos de comparação, esse triângulo corresponde ao triângulo  a area
a area  quando não existir um tal triângulo e
quando não existir um tal triângulo e  quando todos estes triângulos forem disjuntos de
quando todos estes triângulos forem disjuntos de  , o conjunto dos
, o conjunto dos  fica reduzida ao estudo do comportamento da função
fica reduzida ao estudo do comportamento da função 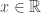 , denotamos por
, denotamos por
 ,
,  , descrever como o comportamento da sequência
, descrever como o comportamento da sequência  no circulo
no circulo 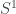 .
.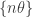 é densa no circulo
é densa no circulo  irracional. Outro resultado classico de
irracional. Outro resultado classico de  irracional) é
irracional) é  ,
, quando
quando  denota o comprimento de
denota o comprimento de  é equidistribuida para quase todo
é equidistribuida para quase todo  (apesar de certos casos especificos tais como
(apesar de certos casos especificos tais como  ainda estarem em aberto). Em geral, temos o
ainda estarem em aberto). Em geral, temos o  para
para  . Um primeiro resultado elementar sobre essa sequência é o fato dela ser equidistribuida:
. Um primeiro resultado elementar sobre essa sequência é o fato dela ser equidistribuida: , use que
, use que 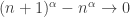 e
e 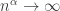 quando
quando  )
) são as componentes conexas de
são as componentes conexas de 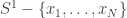 . Note que a soma dos comprimentos
. Note que a soma dos comprimentos  das lacunas
das lacunas  é 1, de maneira que a média do tamanho das lacunas é:
é 1, de maneira que a média do tamanho das lacunas é: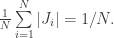
 , temos
, temos![\frac{1}{N}\#\{J\in\mathcal{J}(N): |J|\in [a/N, b/N]\}\to \int_a^b e^{-t} dt](https://s0.wp.com/latex.php?latex=%5Cfrac%7B1%7D%7BN%7D%5C%23%5C%7BJ%5Cin%5Cmathcal%7BJ%7D%28N%29%3A+%7CJ%7C%5Cin+%5Ba%2FN%2C+b%2FN%5D%5C%7D%5Cto+%5Cint_a%5Eb+e%5E%7B-t%7D+dt&bg=ffffff&fg=333333&s=0&c=20201002)
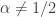 . Mais ainda, M. Boshernitzan observou numericamente em 1993 uma distribuição diferenciada para o caso
. Mais ainda, M. Boshernitzan observou numericamente em 1993 uma distribuição diferenciada para o caso  . Entretanto, a confirmação rigorosa dessa observação numérica de Boshernitzan so foi obtida recentemente por Elkies e McMullen.
. Entretanto, a confirmação rigorosa dessa observação numérica de Boshernitzan so foi obtida recentemente por Elkies e McMullen.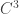 ) nos pontos
) nos pontos 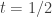 e
e 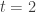 . Ou seja,
. Ou seja,  é a distribuição de lacunas de uma sequência
é a distribuição de lacunas de uma sequência ![\frac{1}{N}\#\{J\in\mathcal{J}(N): |J|\in [a/N, b/N]\}\to \int_a^b G(t) dt](https://s0.wp.com/latex.php?latex=%5Cfrac%7B1%7D%7BN%7D%5C%23%5C%7BJ%5Cin%5Cmathcal%7BJ%7D%28N%29%3A+%7CJ%7C%5Cin+%5Ba%2FN%2C+b%2FN%5D%5C%7D%5Cto+%5Cint_a%5Eb+G%28t%29+dt&bg=ffffff&fg=333333&s=0&c=20201002) quando
quando 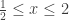 ,
,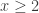 .
.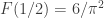 e
e 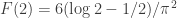 ). Mais ainda,
). Mais ainda,  mas
mas  em
em  quando
quando  . Comparando isso com o exemplo 1, temos que o aparecimento de lacunas grandes é mais provavel para a sequência
. Comparando isso com o exemplo 1, temos que o aparecimento de lacunas grandes é mais provavel para a sequência 